
들어가며
이전 헬싱키 통행시간 데이터 분석 글을 정리하면서, 해당 연구팀이 추후 헬싱키 데이터에 대한 또 다른 논문과 데이터를 배포했다고 잠깐 언급한 바 있다. 오늘은 이건 또 어떤 데이터인지 한번 뜯어볼 계획이다. 이번 데이터셋 관련 상세한 내용은 이 링크의 논문을 참고하면 된다.
본 연구팀은 Elisa Oyj 라는 핀란드 통신사로부터 HSPA(3.5세대 통신망) 통화 기록 데이터를 제공받아 가공하여 생활인구 데이터를 추출했다. 따라서, 본 생활인구는 핀란드 실거주민 뿐 아니라 외국 관광객, 지역외 주민 등을 포함한다.
- c.f.) HSPA(High-Speed Packet Access)는 글로벌 통신망 프로토콜(규격)이다. “업/다운로드 속도가 이 정도되면 HSPA(3.5세대)라 한다.” 같은.
- e.g.) 통신망 프로토콜의 변천사: GSM(2G) » UMTS(3G) » HSPA(3.5G) » HSPA+(3.5G보다는 빠른 수준) » LTE(3.9G) » LTE-Advanced(LTE+ 혹은 LTE-A; 4G) » NR(New Radio; 5G)
Dynamical Population in Helsinki, Finland
1
2
3
4
5
6
7
import os
import json
import numpy as np
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
import matplotlib as mpl
Data Acquisition
- 터미널에서 wget URL을 통해 데이터셋을 다운받을 수 있다.
1 2
>>> wget https://zenodo.org/record/4726996/files/Helsinki_dynpop_matrix.zip?download=1 >>> unzip <downloaded_file> -d <dir_name_after_unzip>
- 내려받은 데이터의 종류는 아래와 같다.
- _workdays.csv: Monday ~ Thursday
- _sat.csv: Saturdays only
- _sun.csv: Sundays only
- .geojson: Helsinki를 포괄하는 13,231개의 250m by 250m 크기의 그리드셀 지리정보
- 2017년 10월 말부터 2018년 1월 초 사이 대략 2달 반 동안의 raw dataset를 기반으로 집계 및 처리한 데이터이다.
- 해당 연구팀은 workdays에 대한 데이터 집계 및 처리 과정에서 금요일은 포함시키지 않았다.
- 개인적인 연구 경험 상으로도 금요일의 패턴은 일반 평일도 아니고, 주말도 아닌 그만의 독특한 패턴을 자주 보인다. 그래서 아마 비슷한 이유로 본 연구팀도 금요일은 배제시켜 평일을 구성한 듯 하다.
- 평일/토요일/일요일별 집계된 데이터셋들은 모두 내부적으로 1시간 단위로 되어 있다.
1
2
3
4
5
6
dataset/
├── [2.5M] HMA_Dynamic_population_24H_sat.csv
├── [2.5M] HMA_Dynamic_population_24H_sun.csv
├── [2.5M] HMA_Dynamic_population_24H_workdays.csv
├── [3.1K] README.txt
└── [4.8M] target_zones_grid250m_EPSG3067.geojson
1
2
3
DataPath = '/home/helsinki/Helsinki_dynpop_matrix'
DataContents = [file for file in os.listdir(DataPath)]
print(DataContents)
1
['target_zones_grid250m_EPSG3067.geojson', 'HMA_Dynamic_population_24H_workdays.csv', 'HMA_Dynamic_population_24H_sat.csv', 'HMA_Dynamic_population_24H_sun.csv', 'README.txt', '.README.txt.swp']
Geojson of Helsinki
“target_zones_grid250m_EPSG3067.geojson”
- Attributes
- YKR_ID: 핀란드어 yhdyskuntarakenteen seurantajärjestelmä의 약자… (핀란드 정부에서 정의한 지질학적 그리드 ID)
- geometry: geometrical POLYGON (EPSG: 3067 / Cartesian axis: East(metre) + North(metre) / Ellipsoid: GRS 1980)
- 13,231개의 독립적인 YKR_ID(grid) 가 존재
1
2
geojson_df = gpd.read_file(os.path.join(DataPath, DataContents[0]))
geojson_df
| YKR_ID | geometry | |
|---|---|---|
| 0 | 5785640 | POLYGON ((382000.00014 6697750.00013, 381750.0... |
| 1 | 5785641 | POLYGON ((382250.00014 6697750.00013, 382000.0... |
| 2 | 5785642 | POLYGON ((382500.00014 6697750.00013, 382250.0... |
| 3 | 5785643 | POLYGON ((382750.00014 6697750.00013, 382500.0... |
| 4 | 5787544 | POLYGON ((381250.00014 6697500.00013, 381000.0... |
| ... | ... | ... |
| 13226 | 6016698 | POLYGON ((373000.00014 6665500.00013, 372750.0... |
| 13227 | 6016699 | POLYGON ((373250.00014 6665500.00013, 373000.0... |
| 13228 | 6018252 | POLYGON ((372500.00014 6665250.00013, 372250.0... |
| 13229 | 6018253 | POLYGON ((372750.00014 6665250.00013, 372500.0... |
| 13230 | 6018254 | POLYGON ((373000.00014 6665250.00013, 372750.0... |
13231 rows × 2 columns
1
2
3
4
fig, ax = plt.subplots(facecolor='w', figsize=(14, 8))
geojson_df.plot(ax=ax, color='w', edgecolor='black', linewidth=0.2)
ax.axis('off')
plt.show()
Helsinki population
- Divided into Workdays(Mon~Thu) / Sat / Sun, seperately.
- 두달 반 가량의 study period 에 대해 aggregate 한 데이터.
- Attributes: [YKR_ID, H0, H1, …, H23]
- Hx: x시 ~ x+1시 사이의 Population ratio
- Population ratio는 특정 시점의 헬싱키 내 관측 인구 수를 100% 라 보았을 때, 각 YKR grid에서 100% 중 몇 %가 있는지를 나타낸 값이다.
- 논문에 따르면 Population ratio을 추산한 대략적인 과정은 아래와 같다.
- (1) 두달 반 가량의 기간 동안, 각 Base Station(BS; 기지국)마다, 해당 기지국에 잡힌 HSPA calls(통화 기록)를 수집한다.
- (2) Workdays / Sat / Sun 마다 ‘median’ of HSPA calls를 구해서 BS에 할당한다. (이미 여기서 aggregate 됨)
- (3) BS 위치에 대해 Voronoi Tessellation을 진행하여 각 BS의 영역권을 구한다.
- (4) YKR 그리드를 바닥에 깐다.
- (5) Voronoi 영역에 ‘grid가 차지하는 비율’로 BS가 가진 calls를 분배한다. (13,231개의 모든 YKR grid가 각각의 calls을 나눠 할당받게 된다)
- (6) 여기까지가 그저그런 정확도를 지닌 일반적인 interpolation 과정이지만, 본 연구팀을 더욱 정밀한 가공을 위해 아래와 같은 추가적인 후처리를 진행한다.
- (7) 여러 Meta 정보들을 여기저기서 가져와서, 한번 더 grid 내 calls를 재할당한다. (MFD interpolation; 자세히 알고싶으면 Järv et al. 2017 참조)
- (8) 이렇게 시간마다, 그리고 YKR grid마다 calls수가 할당되어있다.
- (9) 특정 시간 시점마다 grid의 calls를 ‘전체 calls 수 대비 grid 내 calls 수’란 비율로 전환한다.
- (10) 이게 H0, H1, …, H23 에 들어있는 값이다. (= Population Ratio; 특정 시점에 대해 13,231개 pop을 전부 합하면 약 100(%)이 된다.)
1
2
3
# 본 작업에서는 workdays 집계 데이터만 살펴보았다.
workday_pop = pd.read_csv(os.path.join(DataPath, DataContents[1]))
workday_pop
| YKR_ID | H0 | H1 | H2 | H3 | H4 | H5 | H6 | H7 | H8 | ... | H14 | H15 | H16 | H17 | H18 | H19 | H20 | H21 | H22 | H23 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5785640 | 0.00083 | 0.00078 | 0.00085 | 0.00082 | 0.00075 | 0.00102 | 0.00126 | 0.00149 | 0.00124 | ... | 0.00134 | 0.00156 | 0.00185 | 0.00162 | 0.00145 | 0.00133 | 0.00116 | 0.00103 | 0.00089 | 0.00079 |
| 1 | 5785641 | 0.00185 | 0.00174 | 0.00182 | 0.00177 | 0.00170 | 0.00219 | 0.00250 | 0.00254 | 0.00207 | ... | 0.00228 | 0.00251 | 0.00287 | 0.00286 | 0.00273 | 0.00267 | 0.00255 | 0.00222 | 0.00202 | 0.00184 |
| 2 | 5785642 | 0.00518 | 0.00481 | 0.00489 | 0.00477 | 0.00466 | 0.00593 | 0.00638 | 0.00580 | 0.00479 | ... | 0.00580 | 0.00600 | 0.00660 | 0.00747 | 0.00751 | 0.00763 | 0.00753 | 0.00637 | 0.00580 | 0.00529 |
| 3 | 5785643 | 0.00561 | 0.00524 | 0.00531 | 0.00520 | 0.00512 | 0.00642 | 0.00687 | 0.00614 | 0.00499 | ... | 0.00587 | 0.00610 | 0.00671 | 0.00762 | 0.00767 | 0.00782 | 0.00783 | 0.00670 | 0.00624 | 0.00572 |
| 4 | 5787544 | 0.00088 | 0.00086 | 0.00093 | 0.00092 | 0.00089 | 0.00109 | 0.00128 | 0.00127 | 0.00086 | ... | 0.00062 | 0.00075 | 0.00091 | 0.00084 | 0.00076 | 0.00074 | 0.00081 | 0.00082 | 0.00088 | 0.00083 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 13226 | 6016698 | 0.00047 | 0.00045 | 0.00053 | 0.00053 | 0.00051 | 0.00046 | 0.00040 | 0.00029 | 0.00021 | ... | 0.00018 | 0.00017 | 0.00018 | 0.00020 | 0.00023 | 0.00025 | 0.00028 | 0.00026 | 0.00033 | 0.00039 |
| 13227 | 6016699 | 0.00018 | 0.00017 | 0.00020 | 0.00020 | 0.00020 | 0.00017 | 0.00015 | 0.00010 | 0.00007 | ... | 0.00004 | 0.00004 | 0.00005 | 0.00006 | 0.00007 | 0.00007 | 0.00009 | 0.00009 | 0.00013 | 0.00015 |
| 13228 | 6018252 | 0.00021 | 0.00020 | 0.00023 | 0.00023 | 0.00022 | 0.00020 | 0.00018 | 0.00013 | 0.00009 | ... | 0.00008 | 0.00007 | 0.00008 | 0.00009 | 0.00010 | 0.00011 | 0.00012 | 0.00011 | 0.00015 | 0.00017 |
| 13229 | 6018253 | 0.00018 | 0.00018 | 0.00021 | 0.00021 | 0.00020 | 0.00018 | 0.00016 | 0.00011 | 0.00008 | ... | 0.00006 | 0.00006 | 0.00006 | 0.00007 | 0.00009 | 0.00009 | 0.00011 | 0.00010 | 0.00013 | 0.00015 |
| 13230 | 6018254 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | ... | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 |
13231 rows × 25 columns
A Snaptime for workdays dataset, 08:00 ~ 08:59
- 08:00 ~ 08:59 = a column of ‘H8’
1
2
3
4
5
6
7
8
9
10
11
12
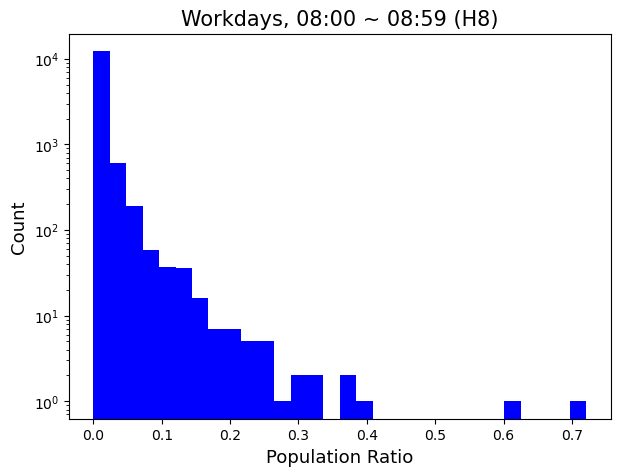
# 13,231개의 YKR grid에 대한 H8 시점의 population ratio 분포
snap_pop = workday_pop.loc[:, ['YKR_ID', 'H8']]
snap_pop = snap_pop.rename(columns={'H8':'pop'})
snap_merge = pd.merge(geojson_df, snap_pop, on='YKR_ID')
fig, ax = plt.subplots(facecolor='w', figsize=(7, 5))
ax.hist(snap_merge['pop'], bins=30, color='blue')
ax.set_ylabel("Count", fontsize=13)
ax.set_xlabel("Population Ratio", fontsize=13)
ax.set_yscale('log')
ax.set_title("Workdays, 08:00 ~ 08:59 (H8)", fontsize=15)
plt.show()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
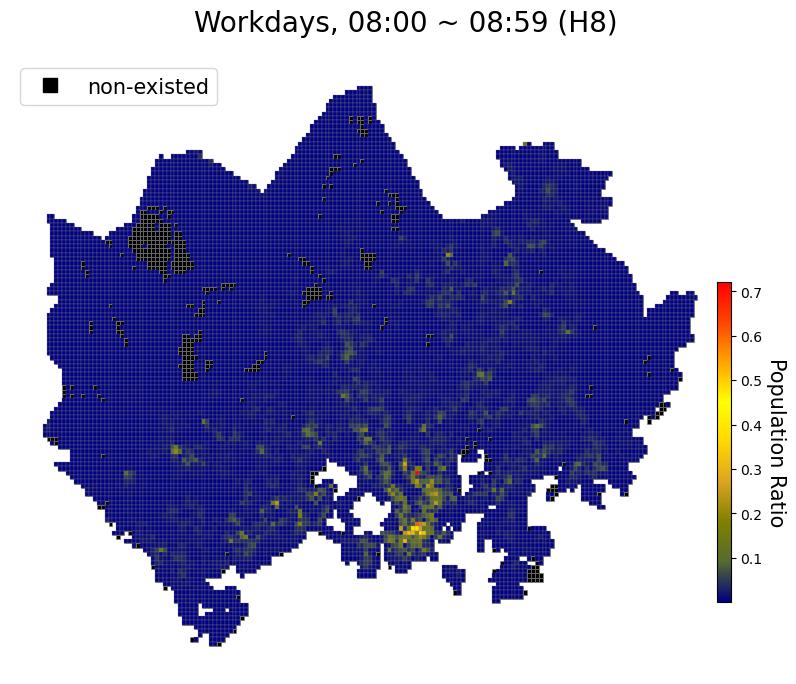
# Spatial Distribution of population ratio
cmap = mpl.colors.LinearSegmentedColormap.from_list("", ["navy", "darkolivegreen", "olive", "goldenrod", "gold", "yellow", "orange", "orangered", "red"])
manual_symbol = mpl.lines.Line2D([0], [0], label='non-existed', marker='s', markersize=10, markeredgecolor='black', markerfacecolor='black', linestyle='')
nonzero_pop_merge = snap_merge[snap_merge['pop']!=0].reset_index(drop=True)
fig, ax = plt.subplots(facecolor='w', figsize=(14, 8))
snap_merge.plot(ax=ax, edgecolor='grey', linewidth=.4, color='black')
nonzero_pop_merge.plot(column='pop', ax=ax, edgecolor='grey', linewidth=0.2, cmap=cmap)
sm = plt.cm.ScalarMappable(norm=plt.Normalize(vmin=nonzero_pop_merge['pop'].min(), vmax=nonzero_pop_merge['pop'].max()), cmap=cmap)
cbaxes = fig.add_axes([0.76, 0.2, 0.01, 0.4])
cbar = fig.colorbar(sm, cax=cbaxes)
cbar.ax.get_yaxis().labelpad = 17
cbar.ax.set_ylabel('Population Ratio', rotation=270, fontsize=15)
ax.legend(loc='upper left', handles=[manual_symbol], prop={'size': 15})
ax.set_title("Workdays, 08:00 ~ 08:59 (H8)", x=.55, y=1.03, fontsize=20)
ax.axis('off')
plt.show()
24h for workdays dataset
- Circadian change of spatial distribution of population ratio.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# Default requirements
timeset = [f"H{time}"for time in range(24)]
cmap = mpl.colors.LinearSegmentedColormap.from_list("", ["navy", "darkolivegreen", "olive", "goldenrod", "gold", "yellow", "orange", "orangered", "red"])
manual_symbol = mpl.lines.Line2D([0], [0], label='non-existed', marker='s', markersize=10, markeredgecolor='black', markerfacecolor='black', linestyle='')
merge_pop = pd.merge(geojson_df, workday_pop, on='YKR_ID')
total_cnt = merge_pop.shape[0]
# Plot for loop
fig, axs = plt.subplots(nrows=6, ncols=4, facecolor='w', figsize=(60, 72))
for time_col, ax in zip(timeset, axs.flatten()):
snap_pop = merge_pop.loc[:, ['YKR_ID', 'geometry', time_col]]
nonzero_snap_pop = snap_pop[snap_pop[time_col]!=0].reset_index(drop=True)
if not nonzero_snap_pop.shape[0] == total_cnt:
snap_pop.plot(ax=ax, edgecolor='grey', linewidth=.4, color='black')
ax.legend(loc='upper left', handles=[manual_symbol], prop={'size': 15})
nonzero_snap_pop.plot(column=time_col, ax=ax, edgecolor='grey', linewidth=.2, cmap=cmap)
sm = plt.cm.ScalarMappable(norm=plt.Normalize(vmin=nonzero_snap_pop[time_col].min(), vmax=nonzero_snap_pop[time_col].max()), cmap=cmap)
cbaxes = ax.inset_axes([0.55, 0.07, 0.5, 0.02])
cbar = fig.colorbar(sm, cax=cbaxes, orientation='horizontal', ticks=None)
time_unit = time_col.split('H')[1]
ax.set_title(f"Workdays, {time_unit}:00 ~ {time_unit}:59 ({time_col})", x=.55, y=1.03, fontsize=14)
ax.axis('off')
plt.subplots_adjust(wspace=.1, hspace=.3)
plt.show()

Take-Home Message and Discussion
- 핀란드의 수도 헬싱키의 생활인구’비율’ 데이터를 살펴보았다.
- 두달 반간의 통화기록 raw dataset을 기반으로 시간 단위(1h resoultion)로 집계 및 가공한 데이터이다.
- Workdays(월~목) / Sat / Sun별로 집계 및 가공되어 공개 배포하고 있다.
- YKR Grid 라는 핀란드 정부에서 정의한 250m by 250m 크기의 grid를 사용하고 있다.
- 헬싱키에 속하는 YKR Grid는 총 13,231개이다.
fin