들어가며
Traffic Velocity Dataset in Xuancheng City, China
오늘은 경기도 면적보다 넓고, 인구수 250만 수준의 중국 쉬안청시 도로망 네트워크와 차량 통행속도 데이터를 살펴보았다. 기존에 수집해온 비슷한 유형의 교통 데이터는 중국 청두시, TOPIS 서울시 뿐이었는데, 이번에 또 꽤 쓸만한 데이터를 알게 되어 이렇게 정리한다.
오늘은 Kepler.gl이라는 Uber에서 개발한 지리정보 시각화 도구(오픈소스)를 데이터 시각화에 활용해보려고 한다. KeplerGL은 지리 공간상의 데이터를 비쥬얼적으로 굉장히 fancy하게 표현해주는 것이 장점이고, 또한 웹 기반의 GUI로 되어 있어서 시각적 디자인 튜닝을 편리하게 조절할 수 있다.
References
1
2
3
4
5
6
7
8
9
10
11
| import os, sys
import numpy as np, pandas as pd, geopandas as gpd
import matplotlib.pyplot as plt
import matplotlib as mpl
import imageio.v3 as iio
from datetime import datetime
from tqdm import tqdm
from shapely.wkt import loads
from keplergl import KeplerGl
import base64
import IPython
|
1
2
| plt.rcParams['xtick.bottom'] = True
plt.rcParams['ytick.left'] = True
|
1
2
3
4
5
6
7
8
| def display_html(intmap):
# 초기에 Visual Studio Code 작업 환경에서 KeplerGl 위젯을 띄우는 과정에서
# 여러 버전 충돌이 발생해서 KeplerGL HTML결과를 출력시키기 위해 임시로 만들어놓은 함수이다.
# 이후 KeplerGL - VScode와 호환되도록 버전을 조정해놔서 해결됐다. 따라서 본문 내용에선 등장하지 않을 함수다.
orig_html = str(intmap._repr_html_(),'utf-8')
b64d_html = base64.b64encode(orig_html.encode('utf-8')).decode('utf-8')
framed_html = f'<iframe src="data:text/html;base64,{b64d_html}" style="width:95%; height: 600px">'
return IPython.display.HTML(framed_html)
|
1
2
3
| DataPath = os.path.join(os.getcwd(), 'dataset/')
DataContents = [f for f in os.listdir(DataPath) if 'csv' in f]
print(DataContents)
|
1
| ['fcd.csv', 'loop.csv', 'road_network_segment_level.csv']
|
road_network_segment_level
쉬안청 도로망(네트워크) 데이터이다. 보다시피 csv 파일로 Geometry Object (LINESTRING)가 텍스트 형태로 저장되어 있어서 shapely 라이브러리를 이용해 형변환이 필요하다.
- Attribute Columns
- cid: 고유 도로링크 아이디. ‘<Upstream Node ID>_<Downstream Node ID>’ 형태로 기입되어 있다.
- nlane: 해당 도로링크의 차선수.
- turn: Downstream Node ID와 이어지는 도로링크들이 현재 cid 관점에서 어떤 방향인지를 나타내는 정보. Hash(#)로 구분되어 있다.
- dnroad: Downstream Node ID와 이어지는 도로링크들의 목록이다. Hash(#)로 구분되어 있다. turn 컬럼 정보와 대응된다.
- geometry: cid 도로링크의 geometry object(LINESTRING) 정보다.
- len: cid 도로링크의 길이. (meter 단위)
1
2
3
4
5
| roadNet = gpd.read_file(os.path.join(DataPath, DataContents[2]))
roadNet = roadNet.loc[:, roadNet.columns[:-1]].rename(columns={'geom':'geometry'})
roadNet['geometry'] = roadNet['geometry'].apply(lambda x: x.replace(';', ',')).apply(loads)
roadNet = gpd.GeoDataFrame(roadNet)
roadNet
|
| cid | nlane | turn | dnroad | geometry | len |
|---|
| 0 | 4393_4423 | 3 | S#U#L | 4423_4471#4423_4393#4423_4448 | LINESTRING (118.72389 30.91600, 118.72484 30.9... | 612.7977763205269 |
|---|
| 1 | 4393_9052 | 0 | L#S#U#R | 9052_8367#9052_9051#9052_4393#9052_9135 | LINESTRING (118.72389 30.91600, 118.72202 30.9... | 1066.4846532943966 |
|---|
| 2 | 4423_4471 | 4 | R#S#U#L | 4471_4440#4471_4493#4471_4423#4471_4496 | LINESTRING (118.72838 30.91995, 118.72875 30.9... | 662.1959670657886 |
|---|
| 3 | 4438_4439 | 0 | S#U | 4439_4448#4439_4438 | LINESTRING (118.71876 30.92117, 118.72082 30.9... | 462.0972608008144 |
|---|
| 4 | 4438_4474 | 2 | R#S#U#L | 4474_4448#4474_4582#4474_4438#4474_4502 | LINESTRING (118.71876 30.92117, 118.71978 30.9... | 411.5472060925527 |
|---|
| ... | ... | ... | ... | ... | ... | ... |
|---|
| 1151 | 9174_9175 | 2 | R#U#S | 9175_5123#9175_9174#9175_9176 | LINESTRING (118.74033 30.96741, 118.74125 30.9... | 257.10801856152284 |
|---|
| 1152 | 5126_9176 | 2 | U#L#S | 9176_5126#9176_9175#9176_8359 | LINESTRING (118.74833 30.96373, 118.74831 30.9... | 629.1683579879818 |
|---|
| 1153 | 9175_9176 | 2 | R#U#L | 9176_5126#9176_9175#9176_8359 | LINESTRING (118.74300 30.96766, 118.74358 30.9... | 224.92700605086367 |
|---|
| 1154 | 9163_9177 | 0 | U#R | 9177_9163#9177_9164 | LINESTRING (118.74841 30.95575, 118.75247 30.9... | 901.4226448771283 |
|---|
| 1155 | 9164_9177 | 0 | L#U | 9177_9163#9177_9164 | LINESTRING (118.76007 30.95548, 118.75731 30.9... | 403.006713622304 |
|---|
1156 rows × 6 columns
평소 도로망 네트워크에 관한 데이터는 [LINK_ID, ST_NODE, ED_NODE, GEOMETRY] 컬럼으로 정리해 활용하는게 익숙해서 그렇게 정리하고자 한다.
1
2
3
4
5
| nodelink_gdf = gpd.GeoDataFrame(columns=['link_id', 'st_node', 'ed_node', 'geometry'])
nodelink_gdf['link_id'] = roadNet['cid']
nodelink_gdf.loc[:, ['st_node', 'ed_node']] = roadNet['cid'].str.split('_', expand=True).values
nodelink_gdf['geometry'] = roadNet['geometry'].values
nodelink_gdf
|
| link_id | st_node | ed_node | geometry |
|---|
| 0 | 4393_4423 | 4393 | 4423 | LINESTRING (118.72389 30.91600, 118.72484 30.9... |
|---|
| 1 | 4393_9052 | 4393 | 9052 | LINESTRING (118.72389 30.91600, 118.72202 30.9... |
|---|
| 2 | 4423_4471 | 4423 | 4471 | LINESTRING (118.72838 30.91995, 118.72875 30.9... |
|---|
| 3 | 4438_4439 | 4438 | 4439 | LINESTRING (118.71876 30.92117, 118.72082 30.9... |
|---|
| 4 | 4438_4474 | 4438 | 4474 | LINESTRING (118.71876 30.92117, 118.71978 30.9... |
|---|
| ... | ... | ... | ... | ... |
|---|
| 1151 | 9174_9175 | 9174 | 9175 | LINESTRING (118.74033 30.96741, 118.74125 30.9... |
|---|
| 1152 | 5126_9176 | 5126 | 9176 | LINESTRING (118.74833 30.96373, 118.74831 30.9... |
|---|
| 1153 | 9175_9176 | 9175 | 9176 | LINESTRING (118.74300 30.96766, 118.74358 30.9... |
|---|
| 1154 | 9163_9177 | 9163 | 9177 | LINESTRING (118.74841 30.95575, 118.75247 30.9... |
|---|
| 1155 | 9164_9177 | 9164 | 9177 | LINESTRING (118.76007 30.95548, 118.75731 30.9... |
|---|
1156 rows × 4 columns
1
2
3
| nodelist = pd.concat([nodelink_gdf['st_node'], nodelink_gdf['ed_node']]).drop_duplicates().values
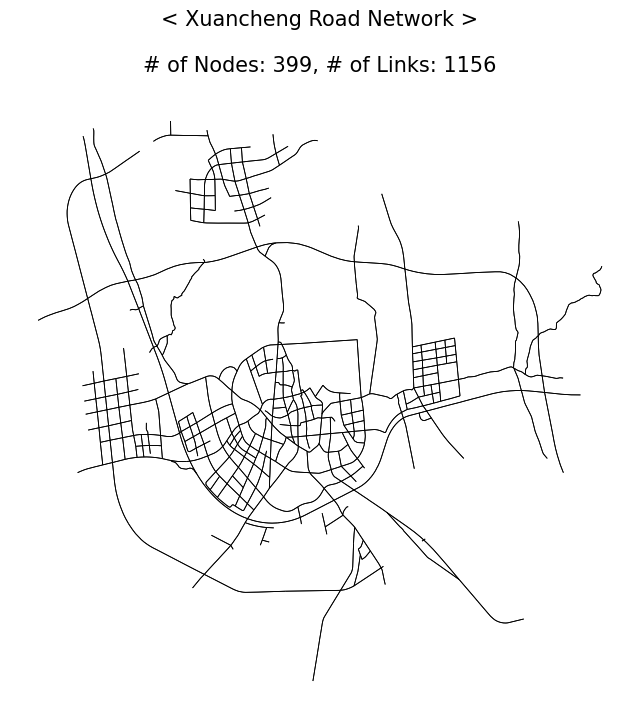
NetSize_str = f"# of Nodes: {len(nodelist)}, # of Links: {nodelink_gdf.shape[0]}"
print(NetSize_str)
|
1
| # of Nodes: 399, # of Links: 1156
|
1
2
3
4
5
6
| fig, ax = plt.subplots(facecolor='w', figsize=(8, 8))
nodelink_gdf.plot(ax=ax, color='black', linewidth=.6)
ax.set_title(f"< Xuancheng Road Network >\n\n{NetSize_str}", fontsize=15, y=1.02)
ax.axis('off')
ax.set_aspect('auto')
plt.show()
|
1
2
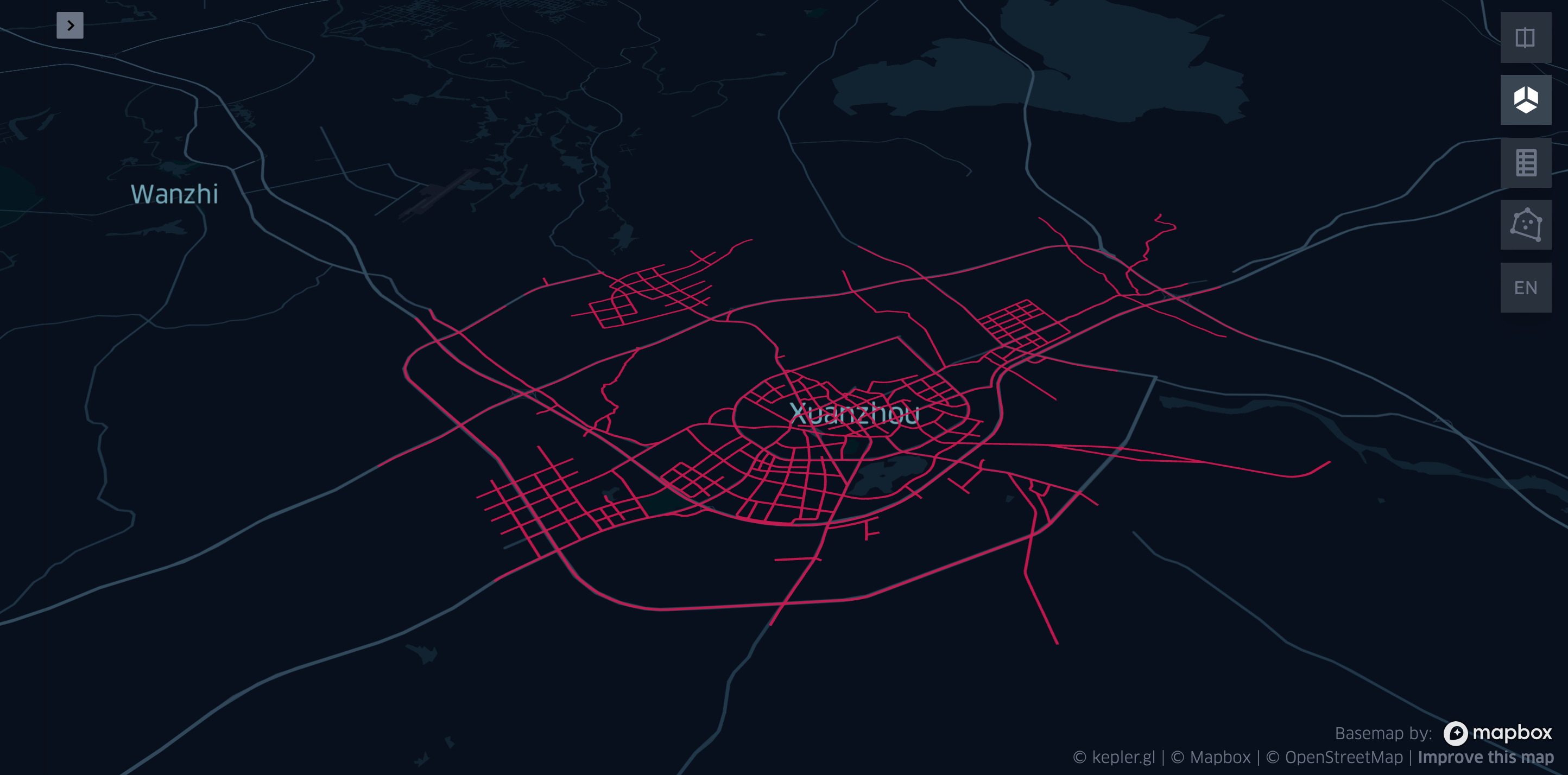
| kepMap = KeplerGl(height=500, show_docs=False)
kepMap.add_data(nodelink_gdf)
|
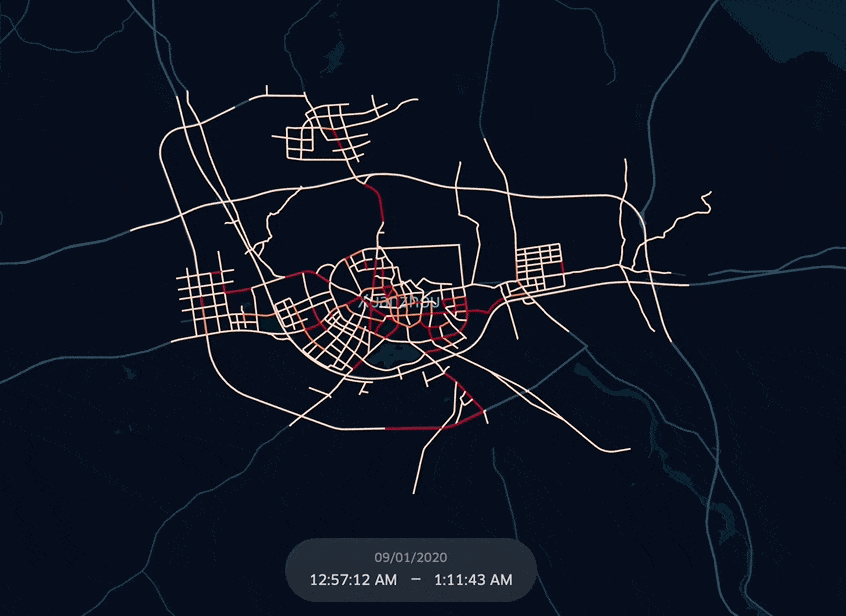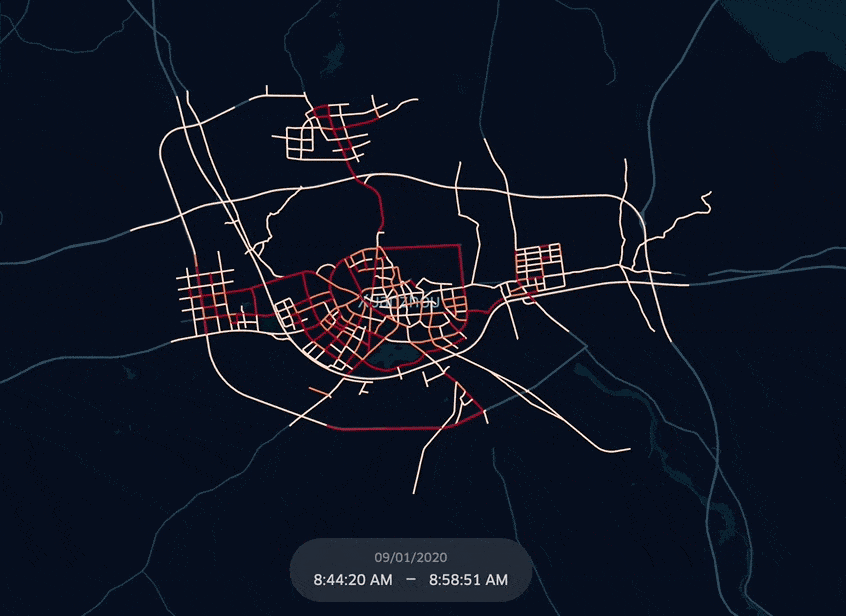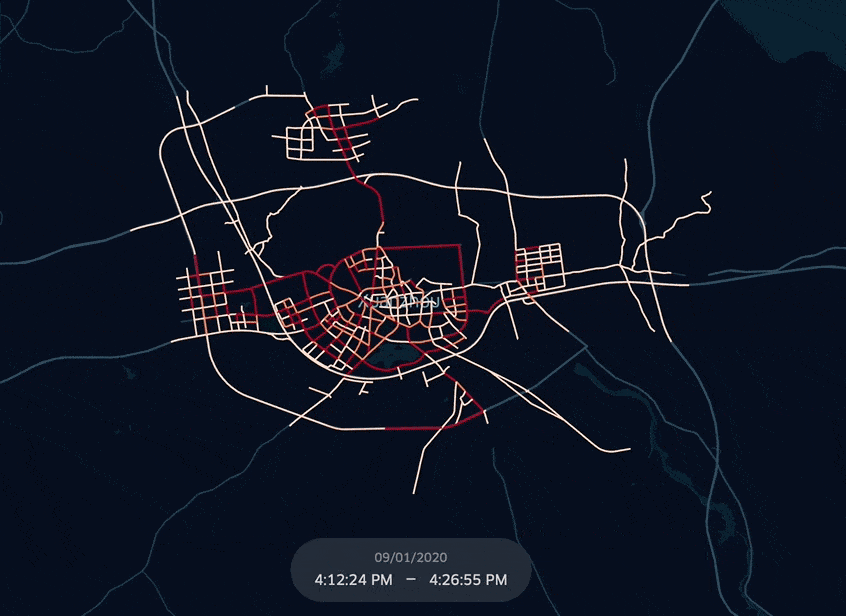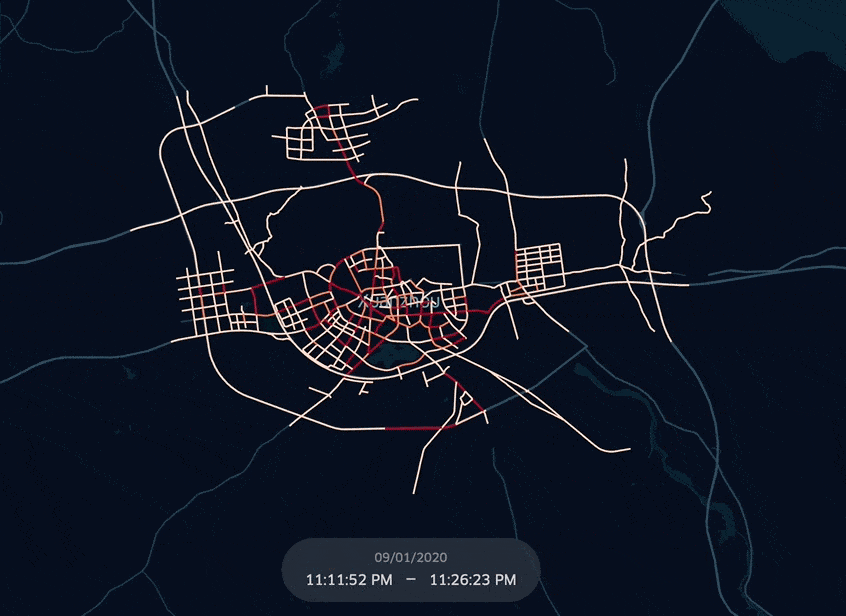
KeplerGL 공식 문서상 EPSG:3857(WGS-84) Projected Coordinate System만 지원하다고 되어 있는데, EPSG:4326 Geographic Coordinate System도 적용되는 걸로 봐선, WGS-84 Datum이면 알아서 transform이 되나보다. 아래는 EPSG:4326 위경도 좌표로 되어있는 도로망 GeoDataFrame을 KeplerGL에 적용한 그림.
fcd
Floating Car Data (FCD)로, 총 500대 상업용 차량(commercial vehicle라고 논문에서 표현)들의 이동 궤적경로를 추적한 데이터다.
- Attribute Columns
- cid: 차량의 고유 아이디
- type: 1 (대형차량), 2 (중형차량)
- time: 10초 단위로 기록된 time-stamp (2020년 9월 1일부터 30일까지; 9월 5일 토요일 하루는 빠져있다.)
- lon / lat: 경/위도 상세정보
- spd / turn: 해당 차량의 속도 / 직진, 우좌회전, 유턴 등에 관한 상태정보
- dis / roadid: Downsteam Node ID까지 남은 거리(meter) / 현재 위치한 도로링크 아이디 (앞선 도로 네트워크절 참고)
1
2
| fcd_dataset = pd.read_csv(os.path.join(DataPath, DataContents[0]))
fcd_dataset
|
| cid | type | time | lon | lat | spd | turn | dis | roadid |
|---|
| 0 | b62b0f461be5ee9702131b83ac8a1abb | 2 | 2020-09-01 10:23:50 | 118.762569 | 30.943402 | 3.127881 | Unknown | 297.148700 | 4724_4664 |
|---|
| 1 | b62b0f461be5ee9702131b83ac8a1abb | 2 | 2020-09-01 10:24:00 | 118.762527 | 30.943123 | 3.127881 | Unknown | 265.869890 | 4724_4664 |
|---|
| 2 | b62b0f461be5ee9702131b83ac8a1abb | 2 | 2020-09-01 10:24:10 | 118.762484 | 30.942844 | 3.127881 | Unknown | 234.591079 | 4724_4664 |
|---|
| 3 | b62b0f461be5ee9702131b83ac8a1abb | 2 | 2020-09-01 10:24:20 | 118.762442 | 30.942565 | 3.127881 | Unknown | 203.312269 | 4724_4664 |
|---|
| 4 | b62b0f461be5ee9702131b83ac8a1abb | 2 | 2020-09-01 10:24:30 | 118.762399 | 30.942286 | 3.127881 | Unknown | 172.033458 | 4724_4664 |
|---|
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
|---|
| 23531690 | 28593fea7959cc1db2b6a5d28e7dbdc5 | 2 | 2020-09-30 00:11:40 | 118.766924 | 30.935829 | 5.607218 | Unknown | 246.717578 | 4554_4634 |
|---|
| 23531691 | 28593fea7959cc1db2b6a5d28e7dbdc5 | 2 | 2020-09-30 00:11:50 | 118.766802 | 30.936322 | 5.607218 | Unknown | 190.645401 | 4554_4634 |
|---|
| 23531692 | 28593fea7959cc1db2b6a5d28e7dbdc5 | 2 | 2020-09-30 00:12:00 | 118.766763 | 30.936825 | 5.607218 | Unknown | 134.573224 | 4554_4634 |
|---|
| 23531693 | 28593fea7959cc1db2b6a5d28e7dbdc5 | 2 | 2020-09-30 00:12:10 | 118.766765 | 30.937329 | 5.607218 | Unknown | 78.501047 | 4554_4634 |
|---|
| 23531694 | 28593fea7959cc1db2b6a5d28e7dbdc5 | 2 | 2020-09-30 00:12:20 | 118.766842 | 30.937828 | 5.607218 | Unknown | 22.428871 | 4554_4634 |
|---|
23531695 rows × 9 columns
1
2
3
4
| fcd_dataset['date'] = fcd_dataset['time'].apply(lambda x: x.split(' ')[0])
aday_fcd = fcd_dataset[fcd_dataset['date']=='2020-09-04'].reset_index(drop=True)
aday_fcd['time'] = aday_fcd['time'].apply(lambda x: datetime.strptime(x, "%Y-%m-%d %H:%M:%S"))
aday_fcd
|
| cid | type | time | lon | lat | spd | turn | dis | roadid | date |
|---|
| 0 | dfe597dd4c4850b695b0461fcea97713 | 2 | 2020-09-04 00:00:00 | 118.737605 | 30.945536 | 8.133786 | Unknown | 411.629553 | 4819_4671 | 2020-09-04 |
|---|
| 1 | 6dd0a76caee6a32bef9c9d230aad3a36 | 2 | 2020-09-04 00:00:00 | 118.767931 | 30.945573 | 6.586755 | L | 378.900480 | 4732_4881 | 2020-09-04 |
|---|
| 2 | 96c3b7a1d33858f5ee8c9cbfa4db1722 | 2 | 2020-09-04 00:00:00 | 118.774699 | 30.939353 | 3.939910 | Unknown | 248.214310 | 4642_4663 | 2020-09-04 |
|---|
| 3 | d91a4682667bd20c72f91e771935ac1d | 2 | 2020-09-04 00:00:00 | 118.743635 | 30.952094 | 6.740968 | R | 115.368304 | 4938_4950 | 2020-09-04 |
|---|
| 4 | a198567247429c5660330023324c5254 | 2 | 2020-09-04 00:00:00 | 118.752775 | 30.947292 | 8.972068 | Unknown | 251.217913 | 4806_4835 | 2020-09-04 |
|---|
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
|---|
| 876356 | a53a02502dced4ad27927d82176a66dc | 2 | 2020-09-04 11:09:00 | 118.751097 | 30.947871 | 3.566932 | Unknown | 167.645786 | 4927_4806 | 2020-09-04 |
|---|
| 876357 | a53a02502dced4ad27927d82176a66dc | 2 | 2020-09-04 11:09:10 | 118.751090 | 30.947550 | 3.566932 | Unknown | 131.976470 | 4927_4806 | 2020-09-04 |
|---|
| 876358 | a53a02502dced4ad27927d82176a66dc | 2 | 2020-09-04 11:09:20 | 118.751083 | 30.947229 | 3.566932 | Unknown | 96.307154 | 4927_4806 | 2020-09-04 |
|---|
| 876359 | a53a02502dced4ad27927d82176a66dc | 2 | 2020-09-04 11:09:30 | 118.751077 | 30.946908 | 3.566932 | Unknown | 60.637838 | 4927_4806 | 2020-09-04 |
|---|
| 876360 | a53a02502dced4ad27927d82176a66dc | 2 | 2020-09-04 11:09:40 | 118.751069 | 30.946587 | 3.566932 | Unknown | 24.968521 | 4927_4806 | 2020-09-04 |
|---|
876361 rows × 10 columns
1
2
3
4
| rand_colors = pd.DataFrame({'cid':aday_fcd['cid'].unique(), 'color':np.random.rand(aday_fcd['cid'].unique().shape[0], 3).tolist()})
aday_fcd = pd.merge(aday_fcd, rand_colors, on='cid')
min_x, min_y, max_x, max_y = nodelink_gdf.total_bounds
aday_fcd = aday_fcd[(aday_fcd['lon'] >= min_x) & (aday_fcd['lon']<=max_x) & (aday_fcd['lat']>=min_y) & (aday_fcd['lat']<=max_y)]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| for ii, timeObj in tqdm(enumerate(sorted(aday_fcd['time'].unique()))):
savepath = os.path.join(os.getcwd(), f"imgs/{timeObj.strftime('%Y%m%d')}")
if not os.path.exists(savepath):
os.mkdir(savepath)
snap_fcd = aday_fcd[aday_fcd['time']==timeObj]
fig, ax = plt.subplots(facecolor='w', figsize=(10, 10))
nodelink_gdf.plot(ax=ax, color='black', linewidth=1.5, alpha=.3)
ax.scatter(snap_fcd['lon'], snap_fcd['lat'], s=13, marker='o', c=snap_fcd['color'])
ax.set_title("< Xuancheng Floating Car Live >\n" + datetime.strftime(timeObj, format="%Y-%m-%d %H:%M:%S"), fontsize=18)
ax.axis('off')
ax.set_aspect('auto')
plt.savefig(os.path.join(savepath, f"{ii}_FCD_snap_Xuancheng.png"), dpi=200, pad_inches=.2, bbox_inches='tight')
plt.close()
* * * * * * * * * * * * * * * * * * * * * * * * *
8638it [49:25, 2.91it/s]
|
1
2
3
4
5
6
7
8
| img_set = []
for file in sorted(os.listdir(savepath), key=lambda x: int(x.split('_')[0]), reverse=False)[:2000]:
img_set.append(iio.imread(os.path.join(savepath, file)))
# 풀버전 GIF는 너무 오래 걸려서 2000장만 진행.
# 풀버전 영상화는 cv2-mp4 video로 만드는게 더 가벼울 것임.
gif_fname = f"FCD_Xuancheng_Live_20200904.gif"
iio.imwrite(os.path.join(os.getcwd(), gif_fname), img_set, fps=20, loop=0)
|
Floating Car LIVE by GIF visualization
근데 수집당시 GPS 오차때문인지, 위치가 튀는 데이터 포인트들이 꽤 보인다.
튀는 데이터 포인트들을 (시각화 작업에서) 배제시킬 수 있는 솔루션
- FCD의 위치컬럼 경위도(lat, lon) 컬럼을 결합시켜 Shapely POINT객체로 변환.
- 이 POINT객체를 도로망 데이터의 LINESTRING 정보에다가 Spatial Join.
- 다시 똑같은 시각화 작업 수순 진행 (아마 이렇게 하면 될듯).
1
2
3
4
| from shapely.geometry import Point
aday_fcd['geometry'] = aday_fcd.apply(lambda row: Point(row['lon'], row['lat']), axis=1)
aday_fcd = gpd.GeoDataFrame(aday_fcd)
aday_fcd.head()
|
| cid | type | time | lon | lat | spd | turn | dis | roadid | date | color | geometry |
|---|
| 0 | dfe597dd4c4850b695b0461fcea97713 | 2 | 2020-09-04 00:00:00 | 118.737605 | 30.945536 | 8.133786 | Unknown | 411.629553 | 4819_4671 | 2020-09-04 | [0.6449022587710721, 0.9422334807661026, 0.002... | POINT (118.73760 30.94554) |
|---|
| 1 | dfe597dd4c4850b695b0461fcea97713 | 2 | 2020-09-04 15:26:10 | 118.739395 | 30.959913 | 10.707280 | Unknown | 586.742296 | 8352_5012 | 2020-09-04 | [0.6449022587710721, 0.9422334807661026, 0.002... | POINT (118.73939 30.95991) |
|---|
| 2 | dfe597dd4c4850b695b0461fcea97713 | 2 | 2020-09-04 15:26:20 | 118.739256 | 30.958942 | 10.707280 | Unknown | 478.086315 | 8352_5012 | 2020-09-04 | [0.6449022587710721, 0.9422334807661026, 0.002... | POINT (118.73926 30.95894) |
|---|
| 3 | dfe597dd4c4850b695b0461fcea97713 | 2 | 2020-09-04 15:26:30 | 118.739118 | 30.957972 | 10.707280 | Unknown | 369.430335 | 8352_5012 | 2020-09-04 | [0.6449022587710721, 0.9422334807661026, 0.002... | POINT (118.73912 30.95797) |
|---|
| 4 | dfe597dd4c4850b695b0461fcea97713 | 2 | 2020-09-04 15:26:40 | 118.738980 | 30.957002 | 10.707280 | Unknown | 260.774354 | 8352_5012 | 2020-09-04 | [0.6449022587710721, 0.9422334807661026, 0.002... | POINT (118.73898 30.95700) |
|---|
추출했던 LINESTRING, POINT SIZE를 기준으로 그림에 포함시킬 LINESTRING BUFFER 크기를 가늠한다.
1
2
3
4
5
6
7
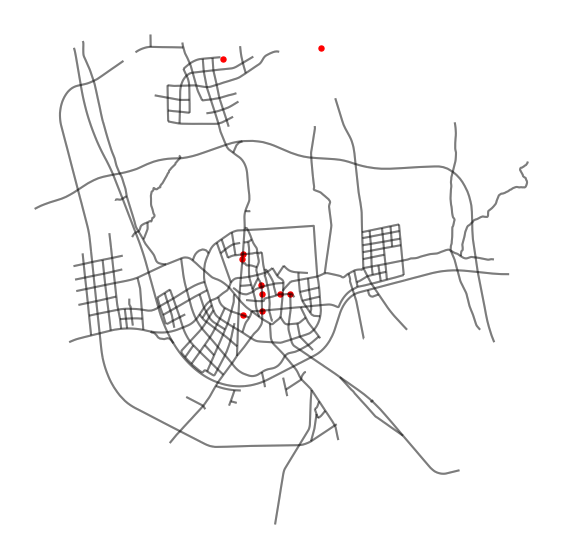
| test_fcd = aday_fcd.sample(n=10) # 10개만 해본다.
fig, ax = plt.subplots(facecolor='w', figsize=(7, 7))
nodelink_gdf.plot(ax=ax, color='black', linewidth=1.5, alpha=.3)
test_fcd.plot(ax=ax, color='red', markersize=13, marker='o')
ax.set_aspect('auto')
ax.axis('off')
plt.show()
|
1
2
3
4
| buff_nodelink_region = nodelink_gdf.buffer(0.001).unary_union
# unary_union은 GeoDataFrame에 들어있는 모든 Geometry Object를 하나의 단일 Polygon 객체로 만들어주는 역할을 한다.
test_fcd[test_fcd.geometry.within(buff_nodelink_region)].shape
|
두 개의 DATA POINT를 날리는게 합리적인 바, LINESTRING의 BUFFER는 0.001이 딱좋을듯 하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # 일부만 할거임
for ii, timeObj in tqdm(enumerate(sorted(aday_fcd['time'].unique())[:2000])):
savepath = os.path.join(os.getcwd(), f"imgs/{timeObj.strftime('%Y%m%d')}/constrained")
if not os.path.exists(savepath):
os.mkdir(savepath)
snap_fcd = aday_fcd[aday_fcd['time']==timeObj]
snap_fcd = snap_fcd[snap_fcd.geometry.within(buff_nodelink_region)]
fig, ax = plt.subplots(facecolor='w', figsize=(10, 10))
nodelink_gdf.plot(ax=ax, color='black', linewidth=1.5, alpha=.3)
ax.scatter(snap_fcd['lon'], snap_fcd['lat'], s=13, marker='o', c=snap_fcd['color'])
ax.set_title("< Xuancheng Floating Car Live >\n" + datetime.strftime(timeObj, format="%Y-%m-%d %H:%M:%S"), fontsize=18)
ax.axis('off')
ax.set_aspect('auto')
plt.savefig(os.path.join(savepath, f"{ii}_FCD_snap_Xuancheng.png"), dpi=200, pad_inches=.2, bbox_inches='tight')
plt.close()
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
2000it [13:17, 2.51it/s]
|
1
2
3
4
5
6
7
8
| img_set = []
for file in sorted(os.listdir(savepath), key=lambda x: int(x.split('_')[0]), reverse=False):
img_set.append(iio.imread(os.path.join(savepath, file)))
# 풀버전 GIF는 너무 오래 걸려서 2000장만 진행.
# 풀버전 영상화는 cv2-mp4 video로 만드는게 더 가벼울 것임.
gif_fname = f"Constrained_FCD_Xuancheng_Live_20200904.gif"
iio.imwrite(os.path.join(os.getcwd(), gif_fname), img_set, fps=20, loop=0)
|
Constrained Floating Car LIVE
확실히 많이 나아졌다. Good!!
하지만 도로망 전체 폴리곤에 인접하기만 하면 포함시키기 때문에, 경로추종은 장담할 수 없다.
loop
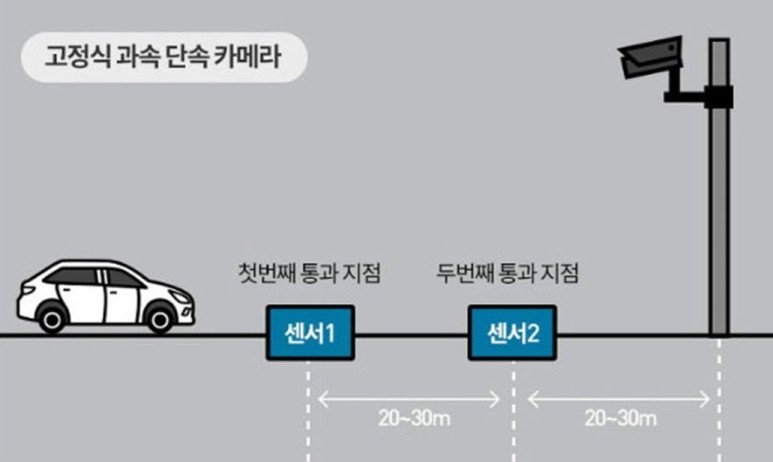
loop 데이터는 Inductive Loop Detector(유도식 루프 감지기)로 수집 및 집계된 도로속도 데이터이다. 쉬안청에서만 볼 수 있는 그런 특별한 장비는 아니고, 우리 일상에서도 쉽게 볼 수 있는 센서다. 도로에서 일상적으로 흔히 볼 수 있는 고정식 과속 단속 카메라 가 그 예시이다. 고정식 과속 단속 카메라 전방에는 아래 그림과 같이 두 개의 센서가 일정한 간격으로 바닥에 설치되어 있는데, 이 두 구간을 차량이 지나갈 때 소요한 시간을 거리와 계산하여 일정 속도 이상의 과속이 인지되면, 플래시와 함께 카메라가 찰칵! 해당 차량을 찍게 되는 원리이다. 이후 LPR(License Plate Recognition; 차량 번호판 인식)을 통해 차량 번호를 인식하고, 식별한 차량에 대한 소유주를 DB에서 찾아 행운의 편지를 자택에 보내주는 것이다.
그림 출처: https://blog.naver.com/geo7319/222288122651
아무튼 저 바닥에 설치된 루프로 수집된 도로 속도 데이터를 집계한 게 여기 loop.csv 데이터이다. 5분 단위로 꽤 해상도가 좋은 데이터인데, 다만 루프가 모든 도로마다 설치되어 있는게 아니다보니 쉬안청의 1156개 도로 전체를 포괄하진 않는 도로속도 데이터이다.
- Attribute Columns
- DET_ID / ROAD_ID: “DET_ID” 루프로 관측된 “ROAD_ID” 도로의
- FTIME / TTIME / INT: “FTIME”부터 “TTIME” 사이 “INT”초 동안 사이의 기록에 의하면,
- COUNT / REG_COUNT / LAR_COUNT: 총 “COUNT”대의 차량이 지나다녔고, 이 중 중형차는 “REG_COUNT”대 & 대형차는 “LAR_COUNT”대이다.
- ARTH_SPD / HARM_SPD: 이들을 집계했을 때, 해당 도로의 평균속도는 시속 “ARTH_SPD”이고 조화평균속도는 “HARM_SPD”이다.
- TURN: 차량들은 현재 “TURN” 방향으로 움직이고 있다.
1
2
3
| lp_dataset = pd.read_csv(os.path.join(DataPath, DataContents[1]))
lp_dataset = lp_dataset.rename(columns={lp_dataset.columns[1]:'ROAD_ID'})
lp_dataset
|
| DET_ID | ROAD_ID | FTIME | TTIME | INT | COUNT | REG_COUNT | LAR_COUNT | ARTH_SPD | HARM_SPD | TURN |
|---|
| 0 | lp_9024_9023 | 9024_9023 | 2020-09-23 01:00:00.0 | 2020-09-23 01:05:00.0 | 300 | 1 | 1 | 0 | 6.408272 | 6.408272 | S |
|---|
| 1 | lp_9024_9023 | 9024_9023 | 2020-09-18 03:05:00.0 | 2020-09-18 03:10:00.0 | 300 | 1 | 1 | 0 | 8.797365 | 8.797365 | L |
|---|
| 2 | lp_9024_9023 | 9024_9023 | 2020-09-22 06:25:00.0 | 2020-09-22 06:30:00.0 | 300 | 1 | 1 | 0 | 8.749707 | 8.749707 | L |
|---|
| 3 | lp_9024_9023 | 9024_9023 | 2020-09-13 06:35:00.0 | 2020-09-13 06:40:00.0 | 300 | 1 | 0 | 1 | 9.270665 | 9.270665 | L |
|---|
| 4 | lp_9024_9023 | 9024_9023 | 2020-09-23 06:00:00.0 | 2020-09-23 06:05:00.0 | 300 | 1 | 1 | 0 | 11.013930 | 11.013930 | L |
|---|
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
|---|
| 5022126 | lp_8446_5125 | 8446_5125 | 2020-09-19 10:30:00.0 | 2020-09-19 10:35:00.0 | 300 | 1 | 1 | 0 | 18.928808 | 18.928808 | S |
|---|
| 5022127 | lp_8446_5125 | 8446_5125 | 2020-09-19 11:05:00.0 | 2020-09-19 11:10:00.0 | 300 | 1 | 1 | 0 | 11.207843 | 11.207843 | S |
|---|
| 5022128 | lp_8446_5125 | 8446_5125 | 2020-09-19 11:25:00.0 | 2020-09-19 11:30:00.0 | 300 | 1 | 0 | 1 | 8.972704 | 8.972704 | S |
|---|
| 5022129 | lp_8446_5125 | 8446_5125 | 2020-09-19 11:55:00.0 | 2020-09-19 12:00:00.0 | 300 | 1 | 1 | 0 | 18.245317 | 18.245317 | S |
|---|
| 5022130 | lp_8446_5125 | 8446_5125 | 2020-09-19 12:15:00.0 | 2020-09-19 12:20:00.0 | 300 | 1 | 0 | 1 | 11.700740 | 11.700740 | S |
|---|
5022131 rows × 11 columns
1
2
3
4
5
6
7
8
| # Remaing the columns we will use
lp_filtered = lp_dataset[['ROAD_ID', 'FTIME', 'ARTH_SPD']]
# Arrange the strings of datetime to fit in KeplerGL
lp_filtered.loc[:, 'FTIME'] = lp_filtered['FTIME'].apply(lambda x: x.split('.')[0]).str.replace('-', '/')
lp_filtered = lp_filtered.rename(columns={'ROAD_ID':'link_id', 'FTIME':'datetime'})
lp_filtered['date'] = lp_filtered['datetime'].apply(lambda x: x.split(' ')[0])
lp_filtered
|
| link_id | datetime | ARTH_SPD | date |
|---|
| 0 | 9024_9023 | 2020/09/23 01:00:00 | 6.408272 | 2020/09/23 |
|---|
| 1 | 9024_9023 | 2020/09/18 03:05:00 | 8.797365 | 2020/09/18 |
|---|
| 2 | 9024_9023 | 2020/09/22 06:25:00 | 8.749707 | 2020/09/22 |
|---|
| 3 | 9024_9023 | 2020/09/13 06:35:00 | 9.270665 | 2020/09/13 |
|---|
| 4 | 9024_9023 | 2020/09/23 06:00:00 | 11.013930 | 2020/09/23 |
|---|
| ... | ... | ... | ... | ... |
|---|
| 5022126 | 8446_5125 | 2020/09/19 10:30:00 | 18.928808 | 2020/09/19 |
|---|
| 5022127 | 8446_5125 | 2020/09/19 11:05:00 | 11.207843 | 2020/09/19 |
|---|
| 5022128 | 8446_5125 | 2020/09/19 11:25:00 | 8.972704 | 2020/09/19 |
|---|
| 5022129 | 8446_5125 | 2020/09/19 11:55:00 | 18.245317 | 2020/09/19 |
|---|
| 5022130 | 8446_5125 | 2020/09/19 12:15:00 | 11.700740 | 2020/09/19 |
|---|
5022131 rows × 4 columns
1
2
3
4
5
6
7
8
9
10
11
12
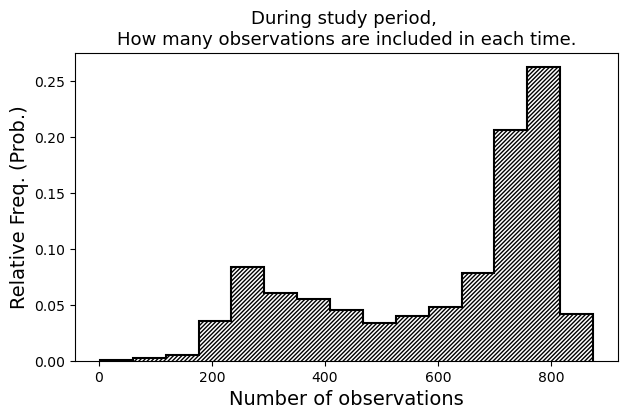
| # During the study period, how many observations are included in.
# 도로속도에 대한 루프 데이터가 관측 시점마다 어느정도 있는지 파악.
EveryMomentCnt = lp_filtered.groupby(by='datetime').count()
fig, ax = plt.subplots(facecolor='w', figsize=(7,4))
ax.hist(EveryMomentCnt['link_id'].values, \
weights=np.zeros_like(EveryMomentCnt['link_id'].values)+1./EveryMomentCnt.shape[0],
bins=15, histtype='step', hatch='////////', color='black', linewidth=1.5)
ax.set_ylabel("Relative Freq. (Prob.)", fontsize=14)
ax.set_xlabel("Number of observations", fontsize=14)
ax.set_title("During study period, \nHow many observations are included in each time.", fontsize=13)
plt.show()
|
대부분의 timestamp 마다 700여개 이상의 도로속도 데이터가 존재하지만, 총 1156개 도로의 전체 도로망 크기에 비해 굉장히 적게 수집된 시점들도 꽤 있다.
Outlier Detection and Removal for loop dataset
데이터가 시점마다 누락도 많고, 분위기가 심상치 않다.
1
| lp_filtered['ARTH_SPD'].describe()
|
1
2
3
4
5
6
7
8
9
| count 5.022131e+06
mean inf
std inf
min 6.701337e-01
25% 6.508745e+00
50% 8.702212e+00
75% 1.104591e+01
max 1.797693e+308
Name: ARTH_SPD, dtype: float64
|
역시 심상치 않다. 평균속도(ARTH_SPD) 상위 40개 정도 뽑아보자.
1
| lp_filtered.nlargest(40, columns='ARTH_SPD')
|
| link_id | datetime | ARTH_SPD | date |
|---|
| 2140487 | 9157_8345 | 2020/09/10 05:30:00 | 1.797693e+308 | 2020/09/10 |
|---|
| 2140567 | 9157_8345 | 2020/09/10 09:15:00 | 1.797693e+308 | 2020/09/10 |
|---|
| 2140629 | 9157_8345 | 2020/09/10 12:05:00 | 1.797693e+308 | 2020/09/10 |
|---|
| 2140562 | 9157_8345 | 2020/09/10 09:00:00 | 1.198462e+308 | 2020/09/10 |
|---|
| 2140615 | 9157_8345 | 2020/09/10 11:25:00 | 1.198462e+308 | 2020/09/10 |
|---|
| 2140453 | 9157_8345 | 2020/09/10 03:25:00 | 8.988466e+307 | 2020/09/10 |
|---|
| 2140464 | 9157_8345 | 2020/09/10 04:20:00 | 8.988466e+307 | 2020/09/10 |
|---|
| 2140465 | 9157_8345 | 2020/09/10 04:20:00 | 8.988466e+307 | 2020/09/10 |
|---|
| 2140483 | 9157_8345 | 2020/09/10 05:20:00 | 8.988466e+307 | 2020/09/10 |
|---|
| 2140506 | 9157_8345 | 2020/09/10 06:25:00 | 8.988466e+307 | 2020/09/10 |
|---|
| 2140523 | 9157_8345 | 2020/09/10 07:10:00 | 8.988466e+307 | 2020/09/10 |
|---|
| 2140574 | 9157_8345 | 2020/09/10 09:35:00 | 8.988466e+307 | 2020/09/10 |
|---|
| 2140619 | 9157_8345 | 2020/09/10 11:35:00 | 8.988466e+307 | 2020/09/10 |
|---|
| 2140649 | 9157_8345 | 2020/09/10 13:05:00 | 8.988466e+307 | 2020/09/10 |
|---|
| 2140485 | 9157_8345 | 2020/09/10 05:25:00 | 5.992310e+307 | 2020/09/10 |
|---|
| 2140564 | 9157_8345 | 2020/09/10 09:05:00 | 5.992310e+307 | 2020/09/10 |
|---|
| 2140572 | 9157_8345 | 2020/09/10 09:30:00 | 5.992310e+307 | 2020/09/10 |
|---|
| 2140604 | 9157_8345 | 2020/09/10 10:55:00 | 5.992310e+307 | 2020/09/10 |
|---|
| 2140467 | 9157_8345 | 2020/09/10 04:30:00 | 4.494233e+307 | 2020/09/10 |
|---|
| 2140548 | 9157_8345 | 2020/09/10 08:20:00 | 4.494233e+307 | 2020/09/10 |
|---|
| 2140486 | 9157_8345 | 2020/09/10 05:25:00 | 3.595386e+307 | 2020/09/10 |
|---|
| 2140494 | 9157_8345 | 2020/09/10 05:50:00 | 3.595386e+307 | 2020/09/10 |
|---|
| 2140538 | 9157_8345 | 2020/09/10 07:50:00 | 2.996155e+307 | 2020/09/10 |
|---|
| 2140616 | 9157_8345 | 2020/09/10 11:25:00 | 2.568133e+307 | 2020/09/10 |
|---|
| 2140585 | 9157_8345 | 2020/09/10 10:00:00 | 1.198462e+307 | 2020/09/10 |
|---|
| 2140544 | 9157_8345 | 2020/09/10 08:05:00 | 1.057467e+307 | 2020/09/10 |
|---|
| 2140605 | 9157_8345 | 2020/09/10 10:55:00 | 1.057467e+307 | 2020/09/10 |
|---|
| 2140573 | 9157_8345 | 2020/09/10 09:30:00 | 9.461543e+306 | 2020/09/10 |
|---|
| 2140583 | 9157_8345 | 2020/09/10 09:55:00 | 9.461543e+306 | 2020/09/10 |
|---|
| 2140593 | 9157_8345 | 2020/09/10 10:20:00 | 8.988466e+306 | 2020/09/10 |
|---|
| 2140587 | 9157_8345 | 2020/09/10 10:05:00 | 8.560443e+306 | 2020/09/10 |
|---|
| 2140628 | 9157_8345 | 2020/09/10 12:00:00 | 7.490388e+306 | 2020/09/10 |
|---|
| 2140520 | 9157_8345 | 2020/09/10 07:00:00 | 6.914204e+306 | 2020/09/10 |
|---|
| 2140547 | 9157_8345 | 2020/09/10 08:15:00 | 6.914204e+306 | 2020/09/10 |
|---|
| 2140554 | 9157_8345 | 2020/09/10 08:35:00 | 6.914204e+306 | 2020/09/10 |
|---|
| 2140539 | 9157_8345 | 2020/09/10 07:50:00 | 6.658123e+306 | 2020/09/10 |
|---|
| 2524052 | 4655_4674 | 2020/09/26 06:15:00 | 4.562472e+05 | 2020/09/26 |
|---|
| 2524125 | 4655_4674 | 2020/09/26 08:20:00 | 2.281318e+05 | 2020/09/26 |
|---|
| 1454116 | 9031_9032 | 2020/09/29 07:25:00 | 5.280798e+04 | 2020/09/29 |
|---|
| 1045054 | 4732_4634 | 2020/09/08 12:05:00 | 2.934272e+04 | 2020/09/08 |
|---|
1
2
3
4
| # 차량들의 평균속도가 10^306 km/h로 관측된 어마무시한 도로(link_id: 9157_8345)가 있다.
# 상대성이론에 위반하므로 이 도로 기록들은 데이터셋에서 일단 제거하자.
lp_filtered = lp_filtered[~lp_filtered.index.isin(lp_filtered.nlargest(36, columns='ARTH_SPD').index)].reset_index(drop=True)
lp_filtered['ARTH_SPD'].describe()
|
1
2
3
4
5
6
7
8
9
| count 5.022095e+06
mean 9.428849e+00
std 2.314950e+02
min 6.701337e-01
25% 6.508715e+00
50% 8.702180e+00
75% 1.104582e+01
max 4.562472e+05
Name: ARTH_SPD, dtype: float64
|
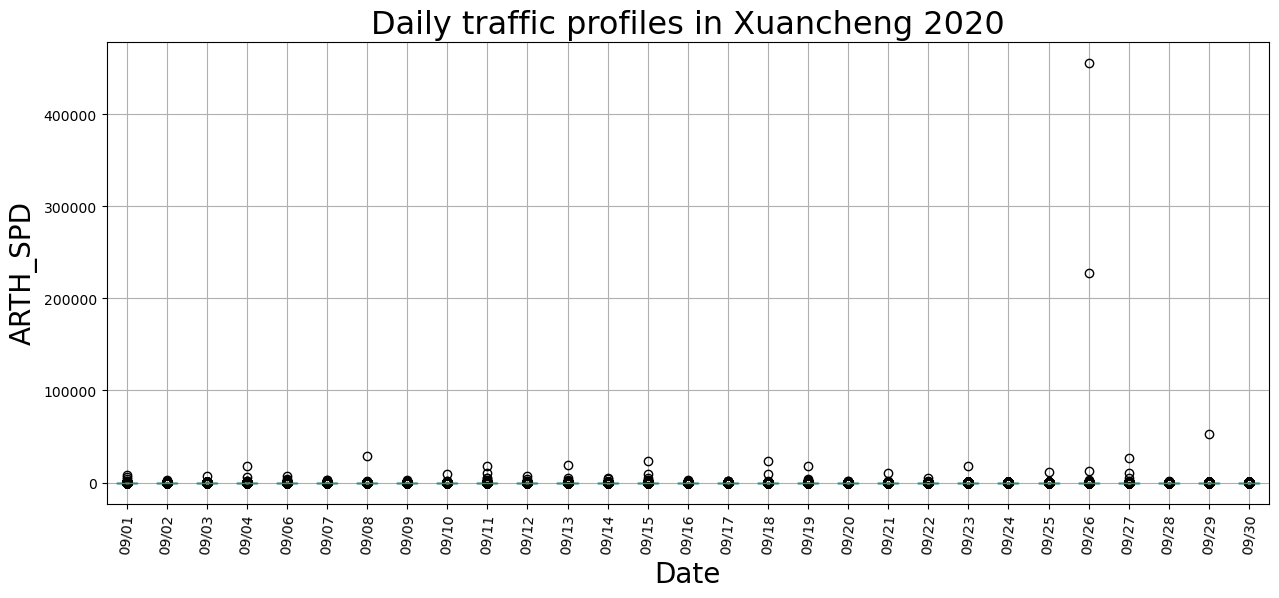
물리적으로 말이 안되는 도로속도 기록들을 제거한 나머지 데이터셋을 가지고, 일별로 boxplot을 그려보자.
1
2
3
4
5
6
7
8
| fig, ax = plt.subplots(facecolor='w', figsize=(15, 6))
lp_filtered.groupby(by='date').boxplot(column='ARTH_SPD', subplots=False, ax=ax, rot=85)
new_xlabs = [x_ticklab.get_text()[6:11] for x_ticklab in ax.get_xticklabels()]
ax.set_xticklabels(new_xlabs)
ax.set_ylabel("ARTH_SPD", fontsize=20)
ax.set_xlabel("Date", fontsize=20)
ax.set_title("Daily traffic profiles in Xuancheng 2020", fontsize=23)
plt.show()
|
특이점을 가진 날들이 꽤 보인다. 간단하게 IQR 탐색방법으로 이상치들을 제거하자.
| link_id | datetime | ARTH_SPD | date |
|---|
| 0 | 9024_9023 | 2020/09/23 01:00:00 | 6.408272 | 2020/09/23 |
|---|
| 1 | 9024_9023 | 2020/09/18 03:05:00 | 8.797365 | 2020/09/18 |
|---|
| 2 | 9024_9023 | 2020/09/22 06:25:00 | 8.749707 | 2020/09/22 |
|---|
| 3 | 9024_9023 | 2020/09/13 06:35:00 | 9.270665 | 2020/09/13 |
|---|
| 4 | 9024_9023 | 2020/09/23 06:00:00 | 11.013930 | 2020/09/23 |
|---|
| ... | ... | ... | ... | ... |
|---|
| 5022090 | 8446_5125 | 2020/09/19 10:30:00 | 18.928808 | 2020/09/19 |
|---|
| 5022091 | 8446_5125 | 2020/09/19 11:05:00 | 11.207843 | 2020/09/19 |
|---|
| 5022092 | 8446_5125 | 2020/09/19 11:25:00 | 8.972704 | 2020/09/19 |
|---|
| 5022093 | 8446_5125 | 2020/09/19 11:55:00 | 18.245317 | 2020/09/19 |
|---|
| 5022094 | 8446_5125 | 2020/09/19 12:15:00 | 11.700740 | 2020/09/19 |
|---|
5022095 rows × 4 columns
1
2
3
4
5
6
7
8
| q1_func = lambda x: np.percentile(x, q=25)
q3_func = lambda x: np.percentile(x, q=75)
q1 = lp_filtered.groupby(by='date')['ARTH_SPD'].transform(q1_func)
q3 = lp_filtered.groupby(by='date')['ARTH_SPD'].transform(q3_func)
iqr = q3-q1
# Query 메소드는 큰 데이터 프레임을 필터링할 때 압도적 성능을 보인다.
new_lp_filtered = lp_filtered.query("(@q1 - 1.5 * @iqr <= ARTH_SPD) & (ARTH_SPD <= @q3 + 1.5 * @iqr)").reset_index(drop=True)
new_lp_filtered
|
| link_id | datetime | ARTH_SPD | date |
|---|
| 0 | 9024_9023 | 2020/09/23 01:00:00 | 6.408272 | 2020/09/23 |
|---|
| 1 | 9024_9023 | 2020/09/18 03:05:00 | 8.797365 | 2020/09/18 |
|---|
| 2 | 9024_9023 | 2020/09/22 06:25:00 | 8.749707 | 2020/09/22 |
|---|
| 3 | 9024_9023 | 2020/09/13 06:35:00 | 9.270665 | 2020/09/13 |
|---|
| 4 | 9024_9023 | 2020/09/23 06:00:00 | 11.013930 | 2020/09/23 |
|---|
| ... | ... | ... | ... | ... |
|---|
| 4906580 | 8446_5125 | 2020/09/19 09:35:00 | 10.858105 | 2020/09/19 |
|---|
| 4906581 | 8446_5125 | 2020/09/19 09:40:00 | 10.545673 | 2020/09/19 |
|---|
| 4906582 | 8446_5125 | 2020/09/19 11:05:00 | 11.207843 | 2020/09/19 |
|---|
| 4906583 | 8446_5125 | 2020/09/19 11:25:00 | 8.972704 | 2020/09/19 |
|---|
| 4906584 | 8446_5125 | 2020/09/19 12:15:00 | 11.700740 | 2020/09/19 |
|---|
4906585 rows × 4 columns
전체 데이터에 약 2% 정도 제거되었다. 다시 박스플롯을 그려보자.
1
2
3
4
5
6
7
8
| fig, ax = plt.subplots(facecolor='w', figsize=(15, 6))
new_lp_filtered.groupby(by='date').boxplot(column='ARTH_SPD', subplots=False, ax=ax, rot=85)
new_xlabs = [x_ticklab.get_text()[6:11] for x_ticklab in ax.get_xticklabels()]
ax.set_xticklabels(new_xlabs)
ax.set_ylabel("ARTH_SPD", fontsize=20)
ax.set_xlabel("Date", fontsize=20)
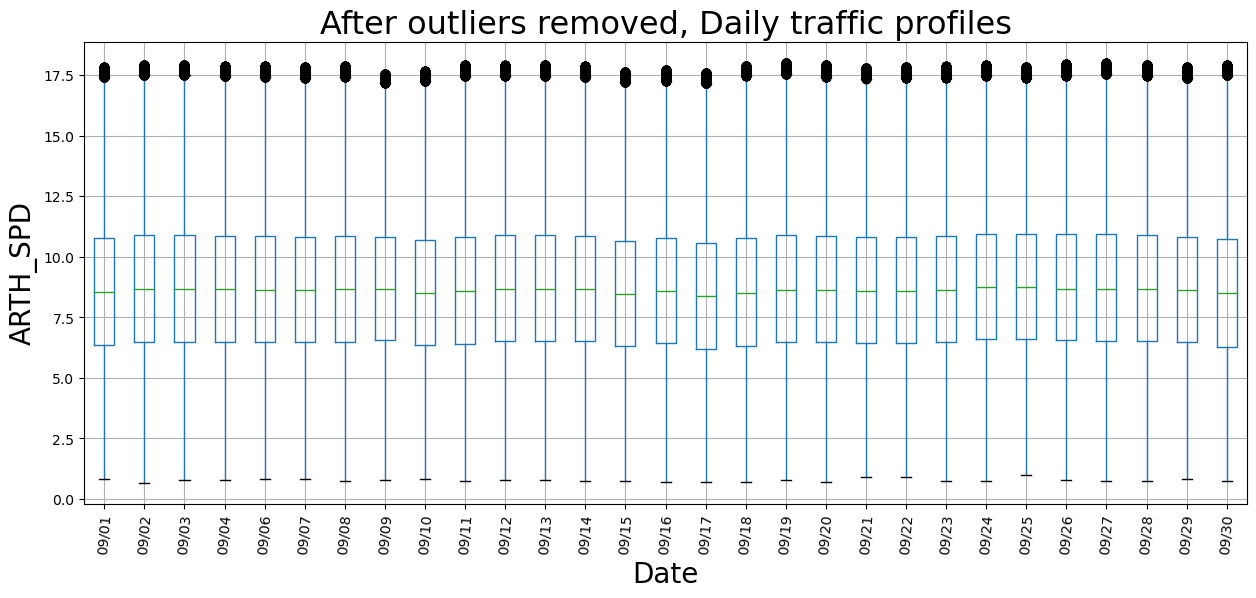
ax.set_title("After outliers removed, Daily traffic profiles", fontsize=23)
plt.show()
|
이정도면 나쁘지 않은 것 같다. 이제 KeplerGL에서 Time Playback 시각화를 해보자.
1
2
3
| # 2020년 9월 1일 평일 하루에 대해서 진행해보기로 한다.
aday_lp_filtered = new_lp_filtered[new_lp_filtered.date=='2020/09/01'].reset_index(drop=True)
aday_lp_filtered
|
| link_id | datetime | ARTH_SPD | date |
|---|
| 0 | 9024_9023 | 2020/09/01 05:40:00 | 10.655903 | 2020/09/01 |
|---|
| 1 | 9024_9023 | 2020/09/01 06:20:00 | 11.161733 | 2020/09/01 |
|---|
| 2 | 9024_9023 | 2020/09/01 06:35:00 | 11.895064 | 2020/09/01 |
|---|
| 3 | 9024_9023 | 2020/09/01 06:35:00 | 3.856741 | 2020/09/01 |
|---|
| 4 | 9024_9023 | 2020/09/01 06:50:00 | 10.558838 | 2020/09/01 |
|---|
| ... | ... | ... | ... | ... |
|---|
| 177219 | 8446_5125 | 2020/09/01 15:25:00 | 11.526395 | 2020/09/01 |
|---|
| 177220 | 8446_5125 | 2020/09/01 16:10:00 | 15.707794 | 2020/09/01 |
|---|
| 177221 | 8446_5125 | 2020/09/01 16:45:00 | 10.858105 | 2020/09/01 |
|---|
| 177222 | 8446_5125 | 2020/09/01 16:50:00 | 8.851162 | 2020/09/01 |
|---|
| 177223 | 8446_5125 | 2020/09/01 18:10:00 | 12.049584 | 2020/09/01 |
|---|
177224 rows × 4 columns
1
2
3
4
| # CHECKPOINT: " For each timestamp, how many observations are included in. "
aday_snap_nums = aday_lp_filtered.groupby(by='datetime')['link_id'].count().reset_index(name='num_of_obs')
time_series = aday_snap_nums['datetime'].apply(lambda x: x.split(' ')[1][:5])
aday_snap_nums
|
| datetime | num_of_obs |
|---|
| 0 | 2020/09/01 00:00:00 | 335 |
|---|
| 1 | 2020/09/01 00:05:00 | 397 |
|---|
| 2 | 2020/09/01 00:10:00 | 417 |
|---|
| 3 | 2020/09/01 00:15:00 | 413 |
|---|
| 4 | 2020/09/01 00:20:00 | 421 |
|---|
| ... | ... | ... |
|---|
| 282 | 2020/09/01 23:30:00 | 407 |
|---|
| 283 | 2020/09/01 23:35:00 | 415 |
|---|
| 284 | 2020/09/01 23:40:00 | 423 |
|---|
| 285 | 2020/09/01 23:45:00 | 380 |
|---|
| 286 | 2020/09/01 23:50:00 | 367 |
|---|
287 rows × 2 columns
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| time_xaxis = [datetime.strptime(i, '%H:%M') for i in time_series]
fig, ax = plt.subplots(facecolor='w', figsize=(10, 4))
# interval 15분으로 plotting.
ax.plot(time_xaxis[::3], aday_snap_nums['num_of_obs'].values[::3], marker='o', color='black', markerfacecolor='w')
ax.axhline(1156, color='red', linewidth=1.2, linestyle='dashed', label='Xuancheng Network Size (# 1156)')
ax.tick_params(axis='both', which='major', labelsize=10)
ax.tick_params(axis='y', which='major', rotation=15, labelsize=9)
fmt = mpl.dates.DateFormatter('%H:%M')
ax.xaxis.set_major_formatter(fmt)
ax.minorticks_on()
ax.tick_params(which='major', length=7, width=1.2, direction='inout')
ax.tick_params(which='minor', length=2, width=1, direction='in', axis='y')
ax.tick_params(which='minor', length=2.2, width=1, direction='out', axis='x')
ax.grid(which='both', axis='y', alpha=0.5)
ax.grid(which='major', axis='x', alpha=0.5)
ax.legend(prop={'size':12})
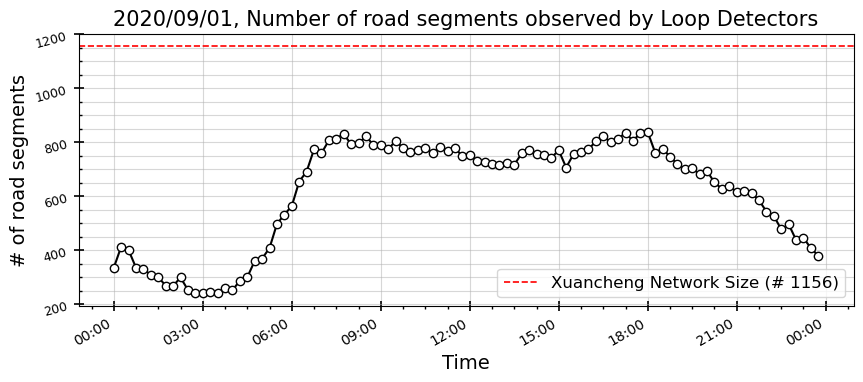
ax.set_title("2020/09/01, Number of road segments observed by Loop Detectors", fontsize=15)
ax.set_ylabel("# of road segments", fontsize=14)
ax.set_xlabel("Time", fontsize=14)
fig.autofmt_xdate()
plt.show()
|
하루 중 교통량 패턴과 유사하다. 루프 감지기로 집계된 loop 데이터도 운행 중인 교통량 크기에 역시 종속될 수 밖에 없나보다.
KeplerGL Map에 데이터를 넣기 전, 전체 네트워크 크기 1156개에 미달하는 만큼 데이터를 interpolation하고자 한다. 사실 그냥 관측되지 않은 (Loop detector 기록에 없는)도로들은 시속 0 (ARTH_SPD=0)으로 채워넣을 것이다.
1
| aday_lp_filtered = aday_lp_filtered[['link_id', 'datetime', 'ARTH_SPD']]
|
1
2
3
4
5
6
7
| # 모든 1156개의 링크를 포괄하는 모든 시점의 데이터프레임(full_df)을 하나 만들고,
full_df = pd.DataFrame([(link_id, timestamp) for link_id in nodelink_gdf['link_id'].unique() for timestamp in aday_lp_filtered['datetime'].unique()], columns=['link_id', 'datetime'])
# full_df를 기준으로 보유 데이터셋을 join merge를 한다.
aday_lp_full = pd.merge(full_df, aday_lp_filtered, how='left', on=['link_id', 'datetime'])
print(aday_lp_full.shape[0])
|
1156개 도로링크 * 287개 시점 = 331772 rows가 되어야 하는데, join을 하고나니 데이터프레임이 더 커졌다.
이런 결과는 데이터에 중복(duplicates)가 있어서 merge시 데이터 크기가 불어났다는 의미다…
1
2
3
4
5
6
| fig, ax = plt.subplots(facecolor='w', figsize=(7,4))
test_num_set = aday_lp_filtered.groupby(by=['link_id', 'datetime']).count()
test_num_set.hist(ax=ax)
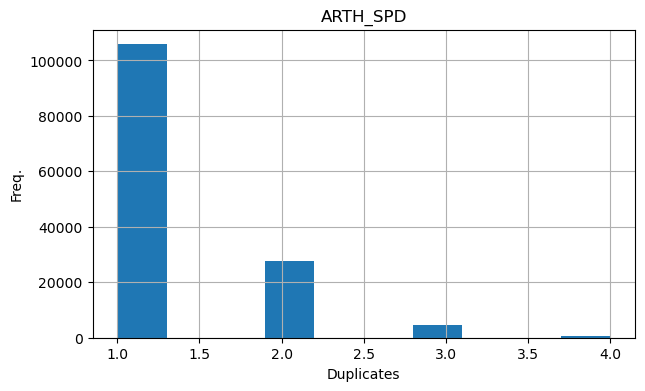
ax.set_ylabel("Freq.", fontsize=10)
ax.set_xlabel("Duplicates", fontsize=10)
plt.show()
|
link_id & datetime 세트가 중복되는 데이터가 2만여개가 있었다.
1
| aday_lp_filtered[(aday_lp_filtered['link_id']=='4393_9052') & (aday_lp_filtered['datetime']=='2020/09/01 07:20:00')]
|
| link_id | datetime | ARTH_SPD |
|---|
| 43953 | 4393_9052 | 2020/09/01 07:20:00 | 9.154108 |
|---|
| 43954 | 4393_9052 | 2020/09/01 07:20:00 | 15.624297 |
|---|
이들의 중복 ARTH_SPD 값들은 평균값으로 대체시키고, 다시 full_df와 merge를 진행해보자..
1
2
3
4
5
6
7
8
| aday_lp_nodup = aday_lp_filtered.groupby(by=['link_id', 'datetime']).mean().reset_index()
# full_df를 기준으로 보유 데이터셋을 join merge를 한다.
aday_lp_full = pd.merge(full_df, aday_lp_nodup, how='left', on=['link_id', 'datetime'])
print(aday_lp_full.shape[0])
# 데이터기록이 없는 도로들의 속도는 0으로 대체
aday_lp_full = aday_lp_full.fillna(0)
|
이제 원하는 full 버전의 dataframe을 얻었다. 1156개의 모든 도로링크들에 대해서, 매 시점별 duplicate / outlier / missing value가 없는 상태의 loop dataset을 만들었다.
이제 도로망 GeoDataFrame과 Merge하고 KeplerGL Map에 이식 후 시각화를 진행해보자.
1
2
3
4
| aday_lp_merged = pd.merge(nodelink_gdf, aday_lp_full, on='link_id')
kepMap = KeplerGl(height=500, show_docs=False)
kepMap.add_data(aday_lp_merged)
kepMap.save_to_html(file_name='Xuancheng_fullLoop_keplerMap.html')
|
Conclusions
중국 쉬안청시의 도로망, 차량 GPS, 도로속도 데이터를 살펴보았다. 간단한 toy model 로 돌리기에 충분한 사이즈의 부담없는 데이터라 꽤 만족스런 줍줍이었다. 다만 GPS 위치의 outlier, 도로속도의 outlier/missing value/duplicates들에 대한 데이터 전처리 작업에 신중을 기해야 할 데이터이다.
이번 활동에서는 사실 KeplerGL을 활용한 시각화를 한번 도전해보는 것에 중점을 뒀었는데, 이에 대한 간단한 소감으론, 활용이 간편하고 시각적으로 매력적이다. Pandas.DataFrame / GeoPandas.GeoDataFrame 하고도 호환이 잘되서, 전처리된 데이터프레임을 바로바로 이식시켜 확인해보기 편하다. Plotly, Folium 과 같은 interactive 파이썬 라이브러리를 이용할 땐 이것저것 사소한 파라미터들을 일일이 다 코딩해줘야 하지만, KeplerGL은 UI로 되어있어서 마우스 버튼 클릭들만으로 설정하고 실시간 확인이 바로바로 가능하다. 다만, 그런 맥락에서 사용자의 자유도가 많이 떨어진다는 느낌을 받았다. 그리고 무엇보다, 커뮤니티에서 이미 많이 나온 이슈같은데, add_data한 데이터프레임의 크기가 커질수록, 추출된 Kepler HTML의 Operating 속도가 상당히 느려진다. 이런 점이 좀 아쉽다. 하지만 OpenCV, imageio 등의 라이브러리 사용없이도 손쉽게 Time-series Video(KeplerGL-Time Playback), 3D 공간 시각화를 구현해주는 건 여전히 매력적인 부분이다.
fin